layout: post title: “Développer une application Flask en Python” date: 2024-10-04 21:30:00 +0002 tags: python flask
Développer une application Flask en Python
📝 Dans ce post, nous allons reprendre les bases de la documentation Flask afin de pouvoir installer notre environnement de développement dans des conditions optimales, de manière à compendre les rouages du module Flask.
Flask
Flask est un micro framework open-source de développement web en Python. Il est classé comme microframework car il est très léger. Flask a pour objectif de garder un noyau simple mais extensible.
Installation
Environnements virtuels
Utilisez un environnement virtuel pour gérer les dépendances de votre projet, tant en développement qu’en production.
Quel problème un environnement virtuel résout-il ? Plus vous avez de projets Python, plus il est probable que vous deviez travailler avec différentes versions des bibliothèques Python, voire de Python lui-même. Des versions plus récentes de bibliothèques pour un projet peuvent rompre la compatibilité dans un autre projet.
Les environnements virtuels sont des groupes indépendants de bibliothèques Python, un pour chaque projet. Les paquets installés pour un projet n’affecteront pas les autres projets ou les paquets du système d’exploitation.
Python est livré avec le module venv pour créer des environnements virtuels.
Créer un environnement
$ mkdir myproject
$ cd myproject
$ python3 -m venv venv
Activez l’environnement
$ . venv/bin/activate
L’invite du shell change pour afficher le nom de l’environnement activé.
Installer Flask
Dans l’environnement activé, utilisez la commande suivante pour installer Flask :
$ pip install Flask
Une application minimale
Une application Flask minimale ressemble à quelque chose comme ceci :
from flask import Flask
app = Flask(__name__)
@app.route("/")
def hello_world():
return "<p>Hello, World!</p>"
Alors, que fait ce code ?
D’abord nous avons importé la classe Flask. Une instance de cette classe sera notre application WSGI.
Ensuite, nous créons une instance de cette classe. Le premier argument est le nom du module ou du paquet de l’application. __name__ est un raccourci pratique qui est approprié pour la plupart des cas. Ceci est nécessaire pour que Flask sache où chercher les ressources telles que les modèles et les fichiers statiques.
Nous utilisons ensuite le décorateur route() pour indiquer à Flask quelle URL doit déclencher notre fonction.
Cette fonction renvoie le message que nous voulons afficher dans le navigateur de l’utilisateur. Le type de contenu par défaut est du HTML, donc le HTML dans la chaîne de caractères sera rendu par le navigateur.
Enregistrez-le sous le nom de hello.py ou quelque chose de similaire. Veillez à ne pas appeler votre application flask.py car cela entrerait en conflit avec Flask lui-même.
Pour démarrer l’application, utilisez la commande flask ou python -m flask. Avant de faire cela, vous devez indiquer à votre terminal l’application avec laquelle travailler en exportant la variable d’environnement FLASK_APP :
$ export FLASK_APP=hello
$ flask run
* Running on http://127.0.0.1:5000/
Détection automatique de l’application
Si le fichier est nommé app.py ou wsgi.py, vous n’avez pas besoin de définir la variable d’environnement FLASK_APP.
Ceci lance un serveur intégré très simple, qui est suffisant pour les tests mais probablement pas ce que vous voulez utiliser en production.
Maintenant, allez sur http://127.0.0.1:5000/, et vous devriez voir votre message d’accueil « Hello, World! ».
Serveur visible de l’extérieur
Si vous démarrez le serveur, vous remarquerez qu’il n’est accessible que depuis votre propre ordinateur, et non depuis un autre ordinateur du réseau. Il s’agit de la valeur par défaut car, en mode débogage, un utilisateur de l’application peut exécuter un code Python arbitraire sur votre ordinateur.
Si vous avez désactivé le débogueur ou si vous faites confiance aux utilisateurs de votre réseau, vous pouvez rendre le serveur accessible au public simplement en ajoutant --host=0.0.0.0 à la ligne de commande :
$ flask run --host=0.0.0.0
Cela indique à votre système d’exploitation d’écouter sur toutes les adresses IP publiques.
L’échappement HTML
Lorsque vous renvoyez du HTML (le type de réponse par défaut dans Flask), toute valeur fournie par l’utilisateur et rendue dans la réponse doit être échappée pour se protéger des attaques par injection. Les modèles HTML rendus avec Jinja, introduits plus tard, le feront automatiquement.
escape(), montré ici, peut être utilisé manuellement. Il est omis dans la plupart des exemples pour des raisons de brièveté, mais vous devriez toujours être conscient de la façon dont vous utilisez les données non fiables.
from markupsafe import escape
@app.route("/<name>")
def hello(name):
return f"Hello, {escape(name)}!"
Si un utilisateur a réussi à soumettre le nom <script>alert("bad")</script>, l’échappement fait en sorte qu’il soit rendu comme du texte, plutôt que d’exécuter le script dans le navigateur de l’utilisateur.
<name> dans la route capture une valeur de l’URL et la passe à la fonction de vue. Ces règles de variables sont expliquées ci-dessous.
Routage
Les applications web modernes utilisent des URL significatives pour aider les utilisateurs. Les utilisateurs sont plus susceptibles d’aimer une page et de revenir si la page utilise une URL significative qu’ils peuvent mémoriser et utiliser pour visiter directement une page.
Utilisez le décorateur route() pour lier une fonction à une URL :
@app.route('/')
def index():
return 'Index Page'
@app.route('/hello')
def hello():
return 'Hello, World'
Vous pouvez faire plus ! Vous pouvez rendre certaines parties de l’URL dynamiques et attacher plusieurs règles à une fonction.
Règles variables
Vous pouvez ajouter des sections variables à une URL en marquant les sections avec <variable_name>. Votre fonction reçoit alors <variable_name> comme un argument nommé. En option, vous pouvez utiliser un convertisseur pour spécifier le type de l’argument comme <converter:variable_name> :
from markupsafe import escape
@app.route('/user/<username>')
def show_user_profile(username):
# show the user profile for that user
return f'User {escape(username)}'
@app.route('/post/<int:post_id>')
def show_post(post_id):
# show the post with the given id, the id is an integer
return f'Post {post_id}'
@app.route('/path/<path:subpath>')
def show_subpath(subpath):
# show the subpath after /path/
return f'Subpath {escape(subpath)}'
Types de convertisseurs :
- string : (par défaut) accepte tout texte sans slash
- int : accepte les nombres entiers positifs
- float : accepte les valeurs positives à virgule flottante
- path : comme string mais accepte aussi les slashs
- uuid : accepte les chaînes UUID
URLs uniques / Comportement de redirection
Les deux règles suivantes diffèrent par l’utilisation d’une barre oblique de fin de ligne :
@app.route('/projects/')
def projects():
return 'The project page'
@app.route('/about')
def about():
return 'The about page'
L’URL canonique du point de terminaison projects comporte un slash de fin. C’est similaire à un dossier dans un système de fichiers. Si vous accédez à l’URL sans slash de fin (/projets), Flask vous redirige vers l’URL canonique avec le slash de fin (/projets/).
L’URL canonique du point de terminaison about ne comporte pas de barre oblique de fin de ligne. Elle est similaire au chemin d’accès d’un fichier. L’accès à l’URL avec un slash de fin (/about/) produit une erreur 404 « Not Found ». Cela permet de conserver des URL uniques pour ces ressources, ce qui aide les moteurs de recherche à ne pas indexer deux fois la même page.
Création d’URL
Pour construire une URL vers une fonction spécifique, utilisez la fonction url_for(). Elle accepte le nom de la fonction comme premier argument et un nombre quelconque d’arguments nommés, chacun correspondant à une partie variable de l’URL. Les parties variables inconnues sont ajoutées à l’URL comme paramètres de requête.
Pourquoi voudriez-vous construire des URL en utilisant la fonction d’inversion d’URL url_for() au lieu de les coder en dur dans vos modèles ?
- L’inversion est souvent plus descriptive que le codage en dur des URL.
- Vous pouvez modifier vos URL en une seule fois au lieu de devoir vous souvenir de modifier manuellement les URL codées en dur.
- La construction d’URL gère l’échappement des caractères spéciaux de manière transparente.
- Les chemins générés sont toujours absolus, ce qui évite le comportement inattendu des chemins relatifs dans les navigateurs.
- Si votre application est placée en dehors de la racine de l’URL, par exemple, dans
/myapplicationau lieu de/,url_for()gère cela correctement pour vous.
Par exemple, ici nous utilisons la méthode test_request_context() pour essayer url_for(). test_request_context() indique à Flask de se comporter comme s’il traitait une requête même si nous utilisons un shell Python. Voir Contextes locaux.
from flask import url_for
@app.route('/')
def index():
return 'index'
@app.route('/login')
def login():
return 'login'
@app.route('/user/<username>')
def profile(username):
return f'{username}\'s profile'
with app.test_request_context():
print(url_for('index'))
print(url_for('login'))
print(url_for('login', next='/'))
print(url_for('profile', username='John Doe'))
Résultat :
/
/login
/login?next=/
/user/John%20Doe
Méthodes HTTP
Les applications Web utilisent différentes méthodes HTTP pour accéder aux URL. Vous devez vous familiariser avec les méthodes HTTP lorsque vous travaillez avec Flask. Par défaut, une route ne répond qu’aux requêtes GET. Vous pouvez utiliser l’argument methods du décorateur route() pour gérer différentes méthodes HTTP.
from flask import request
@app.route('/login', methods=['GET', 'POST'])
def login():
if request.method == 'POST':
return do_the_login()
else:
return show_the_login_form()
Si GET est présent, Flask ajoute automatiquement le support de la méthode HEAD et traite les requêtes HEAD selon la HTTP RFC. De même, OPTIONS est automatiquement implémenté pour vous.
Fichiers statiques
Les applications web dynamiques ont également besoin de fichiers statiques. C’est généralement de là que proviennent les fichiers CSS et JavaScript. Idéalement, votre serveur web est configuré pour les servir à votre place, mais pendant le développement, Flask peut aussi le faire. Il suffit de créer un dossier appelé static dans votre pacquet ou à côté de votre module et il sera disponible à /static sur l’application.
Pour générer des URL pour les fichiers statiques, utilisez le nom de point de terminaison spécial ‘static’ :
url_for('static', filename='style.css')
Le fichier doit être stocké sur le système de fichiers sous le nom de static/style.css.
Modèles de rendu
Générer du HTML à partir de Python n’est pas amusant, et en fait assez encombrant car vous devez faire l’échappement HTML par vous-même pour garder l’application sécurisée. C’est pourquoi Flask configure automatiquement le moteur de template Jinja2 pour vous.
Pour rendre un modèle, vous pouvez utiliser la méthode render_template(). Tout ce que vous avez à faire est de fournir le nom du modèle et les variables que vous voulez passer au moteur de modèle comme arguments nommés. Voici un exemple simple de la façon de rendre un modèle:
from flask import render_template
@app.route('/hello/')
@app.route('/hello/<name>')
def hello(name=None):
return render_template('hello.html', name=name)
Flask va chercher les modèles dans le dossier templates. Donc si votre application est un module, ce dossier est à côté de ce module, si c’est un paquet, il est en fait à l’intérieur de votre paquet:
- Case 1 : un module:
/application.py /templates /hello.html - Cas 2 : un paquet:
/application /__init__.py /templates /hello.html
Pour les modèles, vous pouvez utiliser toute la puissance des modèles Jinja2. Rendez-vous sur le site officiel Jinja2 Template Documentation pour plus d’informations.
Voici un exemple de modèle :
<!doctype html>
<title>Hello from Flask</title>
{% if name %}
<h1>Hello {{ name }}!</h1>
{% else %}
<h1>Hello, World!</h1>
{% endif %}
À l’intérieur des modèles, vous avez également accès aux objets config, request, session et g [^1] ainsi qu’aux fonctions url_for() et get_flashed_messages().
Les modèles sont particulièrement utiles si l’on utilise l’héritage. Si vous voulez savoir comment cela fonctionne, consultez Template Inheritance. En fait, l’héritage des modèles permet de conserver certains éléments sur chaque page (comme l’en-tête, la navigation et le pied de page).
L’échappement automatique est activé, donc si name contient du HTML, il sera automatiquement échappé. Si vous pouvez faire confiance à une variable et que vous savez que ce sera du HTML sûr (par exemple parce qu’elle provient d’un module qui convertit le balisage wiki en HTML), vous pouvez la marquer comme sûre en utilisant la classe Markup ou en utilisant le filtre |
safe dans le modèle. Consultez la documentation de Jinja 2 pour plus d’exemples. |
Voici une introduction de base au fonctionnement de la classe Markup:
>>> from markupsafe import Markup
>>> Markup('<strong>Hello %s!</strong>') % '<blink>hacker</blink>'
Markup('<strong>Hello <blink>hacker</blink>!</strong>')
>>> Markup.escape('<blink>hacker</blink>')
Markup('<blink>hacker</blink>')
>>> Markup('<em>Marked up</em> » HTML').striptags()
'Marked up \xbb HTML'
[^1] : Vous ne savez pas ce qu’est l’objet g ? C’est un objet dans lequel vous pouvez stocker des informations pour vos propres besoins. Consultez la documentation de flask.g et de Using SQLite 3 with Flask.
Accès aux données de la requête
Pour les applications web, il est crucial de réagir aux données qu’un client envoie au serveur. Dans Flask, ces informations sont fournies par l’objet global request. Si vous avez une certaine expérience de Python, vous vous demandez peut-être comment cet objet peut être global et comment Flask parvient à rester threadsafe. La réponse est : les contextes locaux :
Contextes locaux
?> Informations pour les initiés : Si vous voulez comprendre comment cela fonctionne et comment vous pouvez mettre en œuvre des tests avec des contextes locaux, lisez cette section, sinon passez-la.
Certains objets dans Flask sont des objets globaux, mais pas du genre habituel. Ces objets sont en fait des proxies d’objets qui sont locaux à un contexte spécifique. Quelle belle expression ! Mais c’est en fait assez facile à comprendre.
Imaginez que le contexte soit le thread de traitement. Une requête arrive et le serveur web décide de créer un nouveau thread (ou autre chose, l’objet sous-jacent est capable de gérer des systèmes de concurrence autres que les threads). Lorsque Flask démarre son traitement interne des demandes, il détermine que le thread actuel est le contexte actif et lie l’application actuelle et les environnements WSGI à ce contexte (thread). Il le fait de manière intelligente afin qu’une application puisse invoquer une autre application sans rupture.
Qu’est-ce que cela signifie pour vous ? En fait, vous pouvez ignorer complètement que c’est le cas, à moins que vous ne fassiez des tests unitaires. Vous remarquerez que le code qui dépend d’un objet requête sera soudainement interrompu parce qu’il n’y a pas d’objet requête. La solution consiste à créer vous-même un objet requête et à le lier au contexte. La solution la plus simple pour les tests unitaires est d’utiliser le gestionnaire de contexte test_request_context(). En combinaison avec l’instruction with, il liera une requête de test afin que vous puissiez interagir avec elle. Voici un exemple :
from flask import request
with app.test_request_context('/hello', method='POST'):
# now you can do something with the request until the
# end of the with block, such as basic assertions:
assert request.path == '/hello'
assert request.method == 'POST'
L’autre possibilité est de passer un environnement WSGI entier à la méthode request_context() :
with app.request_context(environ):
assert request.method == 'POST'
L’objet Requête
L’objet requête est documenté dans la section API et nous ne le couvrirons pas ici en détail (voir Request). Voici une vue d’ensemble de certaines des opérations les plus courantes. Tout d’abord, vous devez l’importer depuis le module flask :
from flask import request
La méthode de la requête actuelle est disponible en utilisant l’attribut method. Pour accéder aux données de formulaire (données transmises dans une requête POST ou PUT), vous pouvez utiliser l’attribut form. Voici un exemple complet des deux attributs mentionnés ci-dessus :
@app.route('/login', methods=['POST', 'GET'])
def login():
error = None
if request.method == 'POST':
if valid_login(request.form['username'],
request.form['password']):
return log_the_user_in(request.form['username'])
else:
error = 'Invalid username/password'
# the code below is executed if the request method
# was GET or the credentials were invalid
return render_template('login.html', error=error)
Que se passe-t-il si la clé n’existe pas dans l’attribut form ? Dans ce cas, un KeyError spécial est généré. Vous pouvez l’attraper comme une KeyError standard mais si vous ne le faites pas, une page d’erreur HTTP 400 Bad Request est affichée à la place. Ainsi, dans de nombreuses situations, vous n’avez pas à faire face à ce problème.
Pour accéder aux paramètres soumis dans l’URL (?key=value), vous pouvez utiliser l’attribut args :
searchword = request.args.get('key', '')
Nous recommandons d’accéder aux paramètres de l’URL avec get ou en attrapant le KeyError car les utilisateurs peuvent changer l’URL et leur présenter une page 400 bad request dans ce cas n’est pas convivial.
Pour une liste complète des méthodes et des attributs de l’objet requête, consultez la documentation de la Request.
Téléchargements de fichiers
Vous pouvez gérer les fichiers téléchargés avec Flask facilement. Veillez simplement à ne pas oublier de définir l’attribut enctype="multipart/form-data" sur votre formulaire HTML, sinon le navigateur ne transmettra pas du tout vos fichiers.
Les fichiers téléchargés sont stockés en mémoire ou dans un emplacement temporaire du système de fichiers. Vous pouvez accéder à ces fichiers en consultant l’attribut files de l’objet requête. Chaque fichier téléchargé est stocké dans ce dictionnaire. Il se comporte comme un objet Python standard file, mais il possède également une méthode save() qui vous permet de stocker ce fichier sur le système de fichiers du serveur. Voici un exemple simple montrant comment cela fonctionne :
from flask import request
@app.route('/upload', methods=['GET', 'POST'])
def upload_file():
if request.method == 'POST':
f = request.files['the_file']
f.save('/var/www/uploads/uploaded_file.txt')
...
Si vous voulez savoir comment le fichier a été nommé sur le client avant d’être téléchargé dans votre application, vous pouvez accéder à l’attribut filename. Cependant, gardez à l’esprit que cette valeur peut être falsifiée et que vous ne devez donc jamais vous y fier. Si vous voulez utiliser le nom de fichier du client pour stocker le fichier sur le serveur, passez-le par la fonction secure_filename() que Werkzeug vous fournit :
from werkzeug.utils import secure_filename
@app.route('/upload', methods=['GET', 'POST'])
def upload_file():
if request.method == 'POST':
file = request.files['the_file']
file.save(f"/var/www/uploads/{secure_filename(f.filename)}")
...
Pour de meilleurs exemples, voir Uploading Files.
Cookies
Pour accéder aux cookies, vous pouvez utiliser l’attribut cookies. Pour définir les cookies, vous pouvez utiliser la méthode set_cookie des objets réponses. L’attribut cookies des objets requêtes est un dictionnaire contenant tous les cookies que le client transmet. Si vous souhaitez utiliser des sessions, n’utilisez pas directement les cookies mais plutôt les Sessions de Flask qui ajoutent une certaine sécurité en plus des cookies pour vous.
Cookies de lecture :
from flask import request
@app.route('/')
def index():
username = request.cookies.get('username')
# use cookies.get(key) instead of cookies[key] to not get a
# KeyError if the cookie is missing.
Stockage des cookies :
from flask import make_response
@app.route('/')
def index():
resp = make_response(render_template(...))
resp.set_cookie('username', 'the username')
return resp
Notez que les cookies sont définis sur les objets réponses. Puisque vous ne retournez normalement que des chaînes de caractères depuis les fonctions de vue, Flask les convertira en objets réponses pour vous. Si vous voulez explicitement faire cela, vous pouvez utiliser la fonction make_response() et ensuite la modifier.
Parfois, vous pouvez vouloir définir un cookie à un moment où l’objet réponse n’existe pas encore. Cela est possible en utilisant le motif Deferred Request Callbacks.
Pour cela, voir également À propos des réponses.
Redirections et erreurs
Pour rediriger un utilisateur vers un autre point de terminaison, utilisez la fonction redirect() ; pour interrompre une requête prématurément avec un code d’erreur, utilisez la fonction abort() :
from flask import abort, redirect, url_for
@app.route('/')
def index():
return redirect(url_for('login'))
@app.route('/login')
def login():
abort(401)
this_is_never_executed()
Cet exemple est plutôt inutile car un utilisateur sera redirigé de l’index vers une page à laquelle il ne peut pas accéder (401 signifie accès refusé) mais il montre comment cela fonctionne.
Par défaut, une page d’erreur en noir et blanc est affichée pour chaque code d’erreur. Si vous voulez personnaliser la page d’erreur, vous pouvez utiliser le décorateur errorhandler() :
from flask import render_template
@app.errorhandler(404)
def page_not_found(error):
return render_template('page_not_found.html'), 404
Notez le 404 après l’appel render_template(). Cela indique à Flask que le code d’état de cette page doit être 404, ce qui signifie non trouvé. Par défaut, 200 est supposé, ce qui signifie : tout s’est bien passé.
Voir Traitement des erreurs d’application pour plus de détails.
À propos des réponses
La valeur de retour d’une fonction de vue est automatiquement convertie en objet réponse pour vous. Si la valeur de retour est une chaîne de caractères, elle est convertie en un objet réponse avec la chaîne de caractères comme corps de réponse, un code d’état 200 OK et un mimetype : text/html. Si la valeur de retour est un dict, jsonify() est appelé pour produire une réponse. La logique que Flask applique pour convertir les valeurs de retour en objets réponses est la suivante :
- Si un objet réponse du type correct est renvoyé, il est directement renvoyé depuis la vue.
- S’il s’agit d’une chaîne de caractères, un objet réponse est créé avec ces données et les paramètres par défaut.
- Si c’est un dictionnaire, un objet réponse est créé en utilisant
jsonify. - Si un tuple est retourné, les éléments du tuple peuvent fournir des informations supplémentaires. De tels tuples doivent être sous la forme
(response, status),(response, headers), ou(response, status, headers). La valeur status remplacera le code d’état et headers peut être une liste ou un dictionnaire de valeurs d’en-tête supplémentaires. - Si rien de tout cela ne fonctionne, Flask supposera que la valeur de retour est une application WSGI valide et la convertira en un objet réponse.
Si vous voulez mettre la main sur l’objet réponse résultant dans la vue, vous pouvez utiliser la fonction make_response().
Imaginez que vous ayez une vue comme celle-ci :
from flask import render_template
@app.errorhandler(404)
def not_found(error):
return render_template('error.html'), 404
Vous devez juste envelopper l’expression de retour avec make_response() et récupérer l’objet réponse pour le modifier, puis le retourner :
``` pythonfrom flask import make_response
@app.errorhandler(404) def not_found(error): resp = make_response(render_template(‘error.html’), 404) resp.headers[‘X-Something’] = ‘A value’ return resp
#### API avec JSON
Un format de réponse courant lors de l’écriture d’une API est JSON. Il est facile de commencer à écrire une telle API avec Flask. Si vous retournez un dict depuis une vue, il sera converti en réponse JSON.
``` python
@app.route("/me")
def me_api():
user = get_current_user()
return {
"username": user.username,
"theme": user.theme,
"image": url_for("user_image", filename=user.image),
}
Selon la conception de votre API, vous pouvez vouloir créer des réponses JSON pour des types autres que dict. Dans ce cas, utilisez la fonction jsonify(), qui sérialise tout type de données JSON pris en charge. Vous pouvez également consulter les extensions de la communauté Flask qui prennent en charge des applications plus complexes.
from flask import jsonify
@app.route("/users")
def users_api():
users = get_all_users()
return jsonify([user.to_json() for user in users])
Sessions
En plus de l’objet requête, il existe un second objet appelé session qui permet de stocker des informations spécifiques à un utilisateur d’une requête à l’autre. Cet objet est implémenté par-dessus les cookies et signe les cookies de manière cryptographique. Cela signifie que l’utilisateur peut regarder le contenu de votre cookie mais ne peut pas le modifier, sauf s’il connaît la clé secrète utilisée pour la signature.
Pour utiliser les sessions, vous devez définir une clé secrète. Voici comment les sessions fonctionnent :
from flask import session
# Set the secret key to some random bytes. Keep this really secret!
app.secret_key = b'_5#y2L"F4Q8z\n\xec]/'
@app.route('/')
def index():
if 'username' in session:
return f'Logged in as {session["username"]}'
return 'You are not logged in'
@app.route('/login', methods=['GET', 'POST'])
def login():
if request.method == 'POST':
session['username'] = request.form['username']
return redirect(url_for('index'))
return '''
<form method="post">
<p><input type=text name=username>
<p><input type=submit value=Login>
</form>
'''
@app.route('/logout')
def logout():
# remove the username from the session if it's there
session.pop('username', None)
return redirect(url_for('index'))
Comment générer de bonnes clés secrètes
Une clé secrète doit être aussi aléatoire que possible. Votre système d’exploitation a des moyens de générer des données plutôt aléatoires basées sur un générateur aléatoire cryptographique. Utilisez la commande suivante pour générer rapidement une valeur pour Flask.secret_key (ou SECRET_KEY) :
$ python -c 'import os; print(os.urandom(16))'
b'_5#y2L"F4Q8z\n\xec]/'
Une note sur les sessions basées sur les cookies : Flask prendra les valeurs que vous mettez dans l’objet session et les sérialisera dans un cookie. Si vous constatez que certaines valeurs ne persistent pas entre les requêtes, que les cookies sont bien activés et que vous n’obtenez pas de message d’erreur clair, vérifiez la taille du cookie dans les réponses de votre page par rapport à la taille prise en charge par les navigateurs web.
Outre les sessions côté client par défaut, si vous souhaitez gérer les sessions côté serveur, plusieurs extensions Flask le permettent.
Message flash
Les applications et les interfaces utilisateur de qualité reposent sur le retour d’information. Si l’utilisateur n’a pas assez de retour, il finira probablement par détester l’application. Flask fournit un moyen très simple de donner un retour à un utilisateur avec le système de flash. Ce système permet essentiellement d’enregistrer un message à la fin d’une requête et d’y accéder lors de la prochaine requête (et seulement la prochaine). Il est généralement associé à un modèle de mise en page pour exposer le message.
Pour flasher un message, utilisez la méthode flash(), pour obtenir les messages, vous pouvez utiliser get_flashed_messages() qui est également disponible dans les modèles. Voir Message Flashing pour un exemple complet.
Journalisation
Parfois, vous pouvez vous trouver dans une situation où vous traitez des données qui devraient être correctes, mais qui ne le sont pas. Par exemple, vous pouvez avoir un code côté client qui envoie une requête HTTP au serveur mais qui est manifestement mal formée. Cela peut être dû à un utilisateur qui modifie les données ou à une défaillance du code client. La plupart du temps, il est normal de répondre par « 400 Bad Request » dans cette situation, mais parfois, cela ne suffit pas et le code doit continuer à fonctionner.
Vous pouvez toujours vouloir enregistrer que quelque chose de louche s’est produit. C’est là que la journalisation est utile. Depuis Flask 0.3, un logger est préconfiguré pour que vous puissiez l’utiliser.
Voici quelques exemples d’appels de journal:
app.logger.debug('A value for debugging')
app.logger.warning('A warning occurred (%d apples)', 42)
app.logger.error('An error occurred')
Le logger attaché est un journal standard Logger, donc allez voir la doc officielle logging pour plus d’informations.
Voir Traitement des erreurs d’application.
Accrochage dans les intergiciels WSGI
Pour ajouter un intergiciel WSGI à votre application Flask, enveloppez l’attribut wsgi_app de l’application. Par exemple, pour appliquer le intergiciel ProxyFix de Werkzeug pour fonctionner derrière Nginx :
from werkzeug.middleware.proxy_fix import ProxyFix
app.wsgi_app = ProxyFix(app.wsgi_app)
Envelopper app.wsgi_app au lieu de app signifie que app pointe toujours vers votre application Flask, et non vers l’intergiciel, donc vous pouvez continuer à utiliser et configurer app directement.
Utiliser les extensions Flask
Les extensions sont des paquets qui vous aident à accomplir des tâches courantes. Par exemple, Flask-SQLAlchemy fournit le support de SQLAlchemy qui rend son utilisation simple et facile avec Flask.
Pour en savoir plus sur les extensions Flask, consultez Extensions.
Déploiement sur un serveur Web
Prêt à déployer votre nouvelle application Flask ? Voir Deployment Options.
Flask Tutorial
📝 Après avoir acquis les bases pour faire du développement d’application Flask, il est temps de passer au tutoriel.
Ce tutoriel vous guidera dans la création d’une application de blog de base appelée Flaskr. Les utilisateurs pourront s’inscrire, se connecter, créer des messages, et modifier ou supprimer leurs propres messages. Vous serez en mesure d’emballer et d’installer l’application sur d’autres ordinateurs.
Il est supposé que vous êtes déjà familier avec Python. Le tutoriel officiel dans les docs Python est un excellent moyen d’apprendre ou de réviser d’abord.
Bien qu’il soit conçu pour donner un bon point de départ, le tutoriel ne couvre pas toutes les fonctionnalités de Flask. Consultez la section Flask pour avoir un aperçu de ce que Flask peut faire, puis plongez dans la documentation pour en savoir plus. Le tutoriel utilise uniquement ce qui est fourni par Flask et Python. Dans un autre projet, vous pourriez décider d’utiliser des Extensions ou d’autres bibliothèques pour simplifier certaines tâches.
Flask est flexible. Il ne vous oblige pas à utiliser un projet ou une disposition de code particuliers. Cependant, au début, il est utile d’utiliser une approche plus structurée. Cela signifie que le tutoriel nécessitera un peu de code passe-partout au départ, mais cela permet d’éviter de nombreux pièges courants que rencontrent les nouveaux développeurs et de créer un projet facile à développer. Lorsque vous serez plus à l’aise avec Flask, vous pourrez sortir de cette structure et profiter pleinement de la flexibilité de Flask.
💡 Le code de cet exemple est disponible sur Github.
Plan du projet
Créez un répertoire de projet et entrez-y :
$ mkdir flask-tutorial
$ cd flask-tutorial
Suivez ensuite les instructions d’installation pour configurer un environnement virtuel Python et installer Flask pour votre projet.
Le tutoriel supposera que vous travaillez dans le répertoire flask-tutorial à partir de maintenant. Les noms de fichiers en haut de chaque bloc de code sont relatifs à ce répertoire.
Une application Flask peut être aussi simple qu’un simple fichier.
hello.py :
from flask import Flask
app = Flask(__name__)
@app.route('/')
def hello():
return 'Hello, World!'
Cependant, lorsqu’un projet prend de l’ampleur, il devient difficile de conserver tout le code dans un seul fichier. Les projets Python utilisent des paquets pour organiser le code en plusieurs modules qui peuvent être importés là où c’est nécessaire, et le tutoriel fera de même.
Le répertoire du projet contiendra :
flaskr/, un paquet Python contenant le code et les fichiers de votre application.tests/, un répertoire contenant les modules de test.venv/, un environnement virtuel Python où Flask et d’autres dépendances sont installées.- Les fichiers d’installation indiquant à Python comment installer votre projet.
- La configuration du contrôle de version, tel que git. Vous devriez prendre l’habitude d’utiliser un certain type de contrôle de version pour tous vos projets, quelle que soit leur taille.
- Tout autre fichier du projet que vous pourriez ajouter à l’avenir.
À la fin, la mise en page de votre projet ressemblera à ceci :
/home/user/Projects/flask-tutorial :
├── flaskr/
│ ├── __init__.py
│ ├── db.py
│ ├── schema.sql
│ ├── auth.py
│ ├── blog.py
│ ├── templates/
│ │ ├── base.html
│ │ ├── auth/
│ │ │ ├── login.html
│ │ │ └── register.html
│ │ └── blog/
│ │ ├── create.html
│ │ ├── index.html
│ │ └── update.html
│ └── static/
│ └── style.css
├── tests/
│ ├── conftest.py
│ ├── data.sql
│ ├── test_factory.py
│ ├── test_db.py
│ ├── test_auth.py
│ └── test_blog.py
├── venv/
├── setup.py
└── MANIFEST.in
Si vous utilisez le contrôle de version, les fichiers suivants, générés lors de l’exécution de votre projet, doivent être ignorés. Il peut y avoir d’autres fichiers en fonction de l’éditeur que vous utilisez. En général, ignorez les fichiers que vous n’avez pas écrits. Par exemple, avec git :
.gitignore :
venv/
*.pyc
__pycache__/
instance/
.pytest_cache/
.coverage
htmlcov/
dist/
build/
*.egg-info/
Configuration de l’application
Une application Flask est une instance de la classe Flask. Tout ce qui concerne l’application, comme la configuration et les URLs, sera enregistré avec cette classe.
La façon la plus simple de créer une application Flask est de créer une instance globale Flask directement en haut de votre code, comme dans l’exemple « Hello, World ! » de la page précédente. Bien que cette méthode soit simple et utile dans certains cas, elle peut poser des problèmes délicats lorsque le projet se développe.
Au lieu de créer une instance Flask globalement, vous la créerez dans une fonction. Cette fonction est connue sous le nom de fabrique d’applications. Toute configuration, tout enregistrement et tout autre réglage dont l’application a besoin se fera dans la fonction, puis l’application sera retournée.
Fabrique d’applications
C’est le moment de commencer à coder ! Créez le répertoire flaskr et ajoutez le fichier __init__.py. Le fichier __init__.py a une double fonction : il contiendra la fabrique de l’application, et il indique à Python que le répertoire flaskr doit être traité comme un paquet.
$ mkdir flaskr
flaskr/init.py :
import os
from flask import Flask
def create_app(test_config=None):
# create and configure the app
app = Flask(__name__, instance_relative_config=True)
app.config.from_mapping(
SECRET_KEY='dev',
DATABASE=os.path.join(app.instance_path, 'flaskr.sqlite'),
)
if test_config is None:
# load the instance config, if it exists, when not testing
app.config.from_pyfile('config.py', silent=True)
else:
# load the test config if passed in
app.config.from_mapping(test_config)
# ensure the instance folder exists
try:
os.makedirs(app.instance_path)
except OSError:
pass
# a simple page that says hello
@app.route('/hello')
def hello():
return 'Hello, World!'
return app
create_app est la fonction de fabrique de l’application. Vous la compléterez plus tard dans le tutoriel, mais elle fait déjà beaucoup.
app = Flask(__name__, instance_relative_config=True)crée l’instanceFlask.__name__est le nom du module Python actuel. L’application a besoin de savoir où il se trouve pour configurer certains chemins, et__name__est un moyen pratique de le lui dire.instance_relative_config=Trueindique à l’application que les fichiers de configuration sont relatifs au dossier instance. Le dossier d’instance est situé en dehors du paquetflaskret peut contenir des données locales qui ne doivent pas être soumises au contrôle de version, comme les secrets de configuration et le fichier de base de données.
app.config.from_mapping()définit une certaine configuration par défaut que l’application utilisera :SECRET_KEYest utilisé par Flask et les extensions pour garder les données en sécurité. Elle est définie à ‘dev’ pour fournir une valeur pratique pendant le développement, mais elle doit être remplacée par une valeur aléatoire lors du déploiement.DATABASEest le chemin où le fichier de la base de données SQLite sera enregistré. Il se trouve sousapp.instance_path, qui est le chemin que Flask a choisi pour le dossier de l’instance. Vous en apprendrez plus sur la base de données dans la section suivante.
app.config.from_pyfile()remplace la configuration par défaut par des valeurs prises dans le fichierconfig.pydu dossier de l’instance s’il existe. Par exemple, lors du déploiement, cela peut être utilisé pour définir une véritableSECRET_KEY.test_configpeut aussi être passé à la fabrique, et sera utilisé à la place de la configuration de l’instance. Ceci afin que les tests que vous écrirez plus tard dans le tutoriel puissent être configurés indépendamment des valeurs de développement que vous avez configurées.
-
os.makedirs()assure queapp.instance_pathexiste. Flask ne crée pas le dossier d’instance automatiquement, mais il doit être créé car votre projet y créera le fichier de la base de données SQLite. @app.route()crée une route simple pour que vous puissiez voir l’application fonctionner avant d’aborder le reste du tutoriel. Elle crée une connexion entre l’URL /hello et une fonction qui renvoie une réponse, la chaîne de caractères ‘Hello, World!’ dans ce cas.
Démarrer l’application
Maintenant vous pouvez démarrer votre application en utilisant la commande flask. Depuis le terminal, dites à Flask où trouver votre application, puis lancez-la en mode développement. Rappelez-vous, vous devriez toujours être dans le répertoire de haut niveau flask-tutorial, pas dans le paquet Flaskr.
Le mode développement affiche un débogueur interactif chaque fois qu’une page lève une exception, et redémarre le serveur chaque fois que vous apportez des modifications au code. Vous pouvez le laisser fonctionner et recharger simplement la page du navigateur pendant que vous suivez le tutoriel.
$ export FLASK_APP=flaskr
$ export FLASK_ENV=development
$ flask run
Vous verrez un résultat similaire à celui-ci :
* Serving Flask app "flaskr"
* Environment: development
* Debug mode: on
* Running on http://127.0.0.1:5000/ (Press CTRL+C to quit)
* Restarting with stat
* Debugger is active!
* Debugger PIN: 855-212-761
Visitez http://127.0.0.1:5000/hello dans un navigateur et vous devriez voir le message « Hello, World ! ». Félicitations, vous avez démarré votre première application web Flask !
Définir et accéder à la base de données
L’application utilisera une base de données SQLite pour stocker les utilisateurs et les messages. Python offre un support intégré pour SQLite dans le module sqlite3.
SQLite est pratique car il ne nécessite pas la mise en place d’un serveur de base de données distinct et est intégré à Python. Cependant, si des requêtes SQL concurrentes essaient d’écrire en même temps dans la base de données, elles ralentiront car chaque écriture se fait de manière séquentielle. Les petites applications ne le remarqueront pas. Une fois que vous aurez atteint une certaine taille, vous voudrez peut-être passer à une autre base de données.
Le tutoriel n’entre pas dans les détails de SQL. Si vous n’êtes pas familier avec ce langage, les documents de SQLite décrivent le language.
Connectez-vous à la base de données
La première chose à faire lorsqu’on travaille avec une base de données SQLite (et la plupart des autres bibliothèques de bases de données Python) est de créer une connexion à celle-ci. Toutes les requêtes et opérations SQL sont effectuées en utilisant cette connexion, qui est fermée une fois le travail terminé.
Dans les applications Web, cette connexion est généralement liée à la requête HTTP en cours. Elle est créée à un moment donné lors du traitement d’une requête HTTP, et fermée avant l’envoi de la réponse.
flaskr/db.py :
import sqlite3
import click
from flask import current_app, g
from flask.cli import with_appcontext
def get_db():
if 'db' not in g:
g.db = sqlite3.connect(
current_app.config['DATABASE'],
detect_types=sqlite3.PARSE_DECLTYPES
)
g.db.row_factory = sqlite3.Row
return g.db
def close_db(e=None):
db = g.pop('db', None)
if db is not None:
db.close()
g est un objet spécial qui est unique pour chaque requête HTTP. Il est utilisé pour stocker les données qui pourraient être accédées par plusieurs fonctions au cours de la requête. La connexion est stockée et réutilisée au lieu de créer une nouvelle connexion si get_db est appelé une seconde fois dans la même requête.
current_app est un autre objet spécial qui pointe vers l’application Flask qui traite la requête HTTP. Puisque vous avez utilisé une fabrique d’application, il n’y a pas d’objet application lorsque vous écrivez le reste de votre code. get_db sera appelé lorsque l’application aura été créée et traitera une requête, donc current_app peut être utilisé.
sqlite3.connect() établit une connexion au fichier pointé par la clé de configuration DATABASE. Ce fichier n’a pas besoin d’exister encore, et n’existera pas tant que vous n’aurez pas initialisé la base de données plus tard.
sqlite3.Row indique à la connexion de retourner des lignes qui se comportent comme des dictionnaires. Cela permet d’accéder aux colonnes par leur nom.
close_db vérifie si une connexion a été créée en vérifiant si g.db a été défini. Si la connexion existe, elle est fermée. Plus loin, vous indiquerez à votre application la fonction close_db dans la fabrique de l’application afin qu’elle soit appelée après chaque requête HTTP.
Créer les tables
Dans SQLite, les données sont stockées dans des tables et des colonnes. Ceux-ci doivent être créés avant que vous puissiez stocker et récupérer des données. Flaskr va stocker les utilisateurs dans la table user, et les messages dans la table post. Créez un fichier avec les commandes SQL nécessaires pour créer des tables vides :
flaskr/schema.sql :
DROP TABLE IF EXISTS user;
DROP TABLE IF EXISTS post;
CREATE TABLE user (
id INTEGER PRIMARY KEY AUTOINCREMENT,
username TEXT UNIQUE NOT NULL,
password TEXT NOT NULL
);
CREATE TABLE post (
id INTEGER PRIMARY KEY AUTOINCREMENT,
author_id INTEGER NOT NULL,
created TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP,
title TEXT NOT NULL,
body TEXT NOT NULL,
FOREIGN KEY (author_id) REFERENCES user (id)
);
Ajoutez les fonctions Python qui exécuteront ces commandes SQL au fichier db.py :
flaskr/db.py :
def init_db():
db = get_db()
with current_app.open_resource('schema.sql') as f:
db.executescript(f.read().decode('utf8'))
@click.command('init-db')
@with_appcontext
def init_db_command():
"""Clear the existing data and create new tables."""
init_db()
click.echo('Initialized the database.')
open_resource() ouvre un fichier relatif au paquet flaskr, ce qui est utile puisque vous ne saurez pas nécessairement où se trouve cet emplacement lors du déploiement ultérieur de l’application. get_db retourne une connexion à la base de données, qui est utilisée pour exécuter les commandes lues dans le fichier.
click.command() définit une commande de ligne de commande appelée init-db qui appelle la fonction init_db et affiche un message de réussite à l’utilisateur. Vous pouvez lire Command Line Interface pour en savoir plus sur l’écriture des commandes.
S’enregistrer auprès de l’application
Les fonctions close_db et init_db_command doivent être enregistrées avec l’instance de l’application ; sinon, elles ne seront pas utilisées par l’application. Cependant, puisque vous utilisez une fonction de fabrique, cette instance n’est pas disponible lors de l’écriture des fonctions. Au lieu de cela, écrivez une fonction qui prend une application et effectue l’enregistrement.
flaskr/db.py :
def init_app(app):
app.teardown_appcontext(close_db)
app.cli.add_command(init_db_command)
app.teardown_appcontext() indique à Flask d’appeler cette fonction lors du nettoyage après le renvoie de la réponse.
app.cli.add_command() ajoute une nouvelle commande qui peut être appelée avec la commande flask.
Importez et appelez cette fonction depuis la fabrique. Placez le nouveau code à la fin de la fonction de la fabrique avant de retourner l’application.
flaskr/init.py :
def create_app():
app = ...
# existing code omitted
from . import db
db.init_app(app)
return app
Initialiser le fichier de la base de données
Maintenant que init-db a été enregistré avec l’application, il peut être appelé en utilisant la commande flask, similaire à la commande run de la page précédente.
📝 Si vous utilisez toujours le serveur de la page précédente, vous pouvez soit arrêter le serveur, soit exécuter cette commande dans un nouveau terminal. Si vous utilisez un nouveau terminal, n’oubliez pas de vous rendre dans le répertoire de votre projet et d’activer l’environnement virtuel comme décrit dans l’Installation. Vous devrez également définir
FLASK_APPetFLASK_ENVcomme indiqué sur la page précédente.
Exécutez la commande init-db :
$ flask init-db
Initialized the database.
Il y aura maintenant un fichier flaskr.sqlite dans le dossier instance de votre projet.
Blueprints et vues
Une fonction de vue est le code que vous écrivez pour répondre aux requêtes adressées à votre application. Flask utilise des modèles pour faire correspondre l’URL de la requête entrante à la vue qui doit la traiter. La vue renvoie des données que Flask transforme en une réponse sortante. Flask peut également aller dans l’autre sens et générer une URL vers une vue basée sur son nom et ses arguments.
Créer un blueprint
Un Blueprint est un moyen d’organiser un groupe de vues et d’autres codes connexes. Plutôt que d’enregistrer des vues et d’autres codes directement dans une application, ils sont enregistrés dans un blueprint. Le blueprint est ensuite enregistré auprès de l’application lorsqu’il est disponible dans la fonction de fabrique.
Flaskr aura deux blueprints, un pour les fonctions d’authentification et un pour les fonctions des articles de blog. Le code de chaque blueprint sera placé dans un module séparé. Puisque le blog a besoin de connaître l’authentification, vous écrirez le module d’authentification en premier.
flaskr/auth.py :
import functools
from flask import (
Blueprint, flash, g, redirect, render_template, request, session, url_for
)
from werkzeug.security import check_password_hash, generate_password_hash
from flaskr.db import get_db
bp = Blueprint('auth', __name__, url_prefix='/auth')
Ceci crée un Blueprint nommé ‘auth’. Comme l’objet application, le blueprint doit savoir où il est défini, donc __name__ est passé comme deuxième argument. Le préfixe url_prefix sera ajouté à toutes les URLs associées au blueprint.
Importez et enregistrez le blueprint depuis la fabrique en utilisant app.register_blueprint(). Placez le nouveau code à la fin de la fonction de la fabrique avant de retourner l’application.
flaskr/init.py :
def create_app():
app = ...
# existing code omitted
from . import auth
app.register_blueprint(auth.bp)
return app
Le blueprint d’authentification comportera des vues permettant d’enregistrer de nouveaux utilisateurs, de se connecter et de se déconnecter.
La première vue : S’inscrire
Lorsque l’utilisateur visite l’URL /auth/register, la vue register renvoie du HTML avec un formulaire qu’il doit remplir. Lorsqu’il soumettra le formulaire, il validera son entrée et soit affichera à nouveau le formulaire avec un message d’erreur, soit créera le nouvel utilisateur et ira à la page de connexion.
Pour l’instant, vous allez juste écrire le code de la vue. À la page suivante, vous écrirez des modèles pour générer le formulaire HTML.
flaskr/auth.py :
@bp.route('/register', methods=('GET', 'POST'))
def register():
if request.method == 'POST':
username = request.form['username']
password = request.form['password']
db = get_db()
error = None
if not username:
error = 'Username is required.'
elif not password:
error = 'Password is required.'
elif db.execute(
'SELECT id FROM user WHERE username = ?', (username,)
).fetchone() is not None:
error = f"User {username} is already registered."
if error is None:
db.execute(
'INSERT INTO user (username, password) VALUES (?, ?)',
(username, generate_password_hash(password))
)
db.commit()
return redirect(url_for('auth.login'))
flash(error)
return render_template('auth/register.html')
Voici ce que fait la fonction de vue register :
-
@bp.routeassocie l’URL/registerà la fonction de vueregister. Lorsque Flask reçoit une requête vers/auth/register, il appelle la vueregisteret utilise la valeur de retour comme réponse. -
Si l’utilisateur a soumis le formulaire,
request.methodsera ‘POST’. Dans ce cas, commencer à valider l’entrée. -
request.formest un type spécial dedictmettant en correspondance les clés et les valeurs du formulaire soumis. L’utilisateur saisira sonusernameet sonpassword. -
Valider que
usernameetpasswordne sont pas vides. -
Valider que
usernamen’est pas déjà enregistré en interrogeant la base de données et en vérifiant si un résultat est retourné.db.executeprend une requête SQL avec des espaces réservés ? pour toute entrée utilisateur, et un tuple de valeurs pour remplacer ces espaces réservés. La bibliothèque de base de données se chargera de l’échappement des valeurs afin que vous ne soyez pas vulnérable à une attaque par injection SQL.
fetchone() renvoie une ligne de la requête. Si la requête n’a donné aucun résultat, elle renvoie None. Plus tard, on utilise fetchall(), qui renvoie une liste de tous les résultats.
-
Si la validation réussit, insérer les nouvelles données de l’utilisateur dans la base de données. Pour des raisons de sécurité, les mots de passe ne doivent jamais être stockés directement dans la base de données. Au lieu de cela,
generate_password_hash()est utilisé pour hacher de manière sécurisée le mot de passe, et ce hash est stocké. Comme cette requête modifie des données,db.commit()doit être appelé ensuite pour enregistrer les modifications. -
Après avoir enregistré l’utilisateur, il est redirigé vers la page de connexion.
url_for()génère l’URL de la vue de connexion en fonction de son nom. C’est préférable à l’écriture directe de l’URL car cela vous permet de changer l’URL plus tard sans modifier tout le code qui y est lié.redirect()génère une réponse de redirection vers l’URL générée. -
Si la validation échoue, l’erreur est affichée à l’utilisateur.
flash()stocke les messages qui peuvent être récupérés lors du rendu du modèle. -
Lorsque l’utilisateur navigue initialement vers auth/register, ou qu’il y a une erreur de validation, une page HTML avec le formulaire d’enregistrement devrait être affichée.
render_template()rendra un modèle contenant le HTML, que vous écrirez dans la prochaine étape du tutoriel.
Connexion
Cette vue suit le même modèle que la vue register ci-dessus.
flaskr/auth.py :
@bp.route('/login', methods=('GET', 'POST'))
def login():
if request.method == 'POST':
username = request.form['username']
password = request.form['password']
db = get_db()
error = None
user = db.execute(
'SELECT * FROM user WHERE username = ?', (username,)
).fetchone()
if user is None:
error = 'Incorrect username.'
elif not check_password_hash(user['password'], password):
error = 'Incorrect password.'
if error is None:
session.clear()
session['user_id'] = user['id']
return redirect(url_for('index'))
flash(error)
return render_template('auth/login.html')
Il y a quelques différences par rapport à la vue register :
-
L’utilisateur est d’abord interrogé et stocké dans une variable pour une utilisation ultérieure.
-
check_password_hash()hache le mot de passe soumis de la même manière que le hash stocké et les compare de manière sécurisée. S’ils correspondent, le mot de passe est valide. -
La
sessionest undictqui stocke les données entre les requêtes. Lorsque la validation réussit, l’idde l’utilisateur est stocké dans une nouvelle session. Les données sont stockées dans un cookie qui est envoyé au navigateur, et le navigateur le renvoie ensuite avec les requêtes suivantes. Flask signe les données de manière sécurisée afin qu’elles ne puissent pas être modifiées.
Maintenant que l’identifiant de l’utilisateur est stocké dans la session, il sera disponible lors des requêtes suivantes. Au début de chaque requête, si un utilisateur est connecté, ses informations doivent être chargées et mises à la disposition des autres vues.
flaskr/auth.py :
@bp.before_app_request
def load_logged_in_user():
user_id = session.get('user_id')
if user_id is None:
g.user = None
else:
g.user = get_db().execute(
'SELECT * FROM user WHERE id = ?', (user_id,)
).fetchone()
bp.before_app_request() enregistre une fonction qui s’exécute avant la fonction de vue, quelle que soit l’URL demandée. load_logged_in_user vérifie si un id d’utilisateur est stocké dans la session et récupère les données de cet utilisateur depuis la base de données, en les stockant sur g.user, qui dure le temps de la requête. S’il n’y a pas d’id utilisateur, ou si l’id n’existe pas, g.user sera None.
Déconnexion
Pour vous déconnecter, vous devez supprimer l’identifiant de l’utilisateur de la session session. Ensuite, load_logged_in_user ne chargera pas un utilisateur lors des requêtes suivantes.
flaskr/auth.py :
@bp.route('/logout')
def logout():
session.clear()
return redirect(url_for('index'))
Exiger l’authentification dans d’autres vues
Pour créer, modifier et supprimer des articles de blog, l’utilisateur doit être connecté. Un décorateur peut être utilisé pour vérifier cela pour chaque vue à laquelle il est appliqué.
flaskr/auth.py :
def login_required(view):
@functools.wraps(view)
def wrapped_view(**kwargs):
if g.user is None:
return redirect(url_for('auth.login'))
return view(**kwargs)
return wrapped_view
Ce décorateur renvoie une nouvelle fonction de vue qui englobe la vue originale à laquelle il est appliqué. La nouvelle fonction vérifie si l’utilisateur existe ou alors redirige vers la page de connexion. Si un utilisateur est défini, la vue originale est appelée et continue normalement. Vous utiliserez ce décorateur lors de l’écriture des vues du blog.
Points de terminaison et URLs
La fonction url_for() génère l’URL d’une vue à partir d’un nom et d’arguments. Le nom associé à une vue est également appelé le point de terminaison, et par défaut, il est identique au nom de la fonction de vue.
Par exemple, la vue hello() qui a été ajoutée à la fabrique d’application plus tôt dans le tutoriel a le nom ‘hello’ et peut être liée avec url_for('hello'). Si elle prenait un argument, ce que vous verrez plus tard, elle serait liée en utilisant url_for('hello', who='World').
Lorsque vous utilisez un blueprint, le nom du blueprint est ajouté au nom de la fonction. Ainsi, le point de terminaison de la fonction login que vous avez écrite ci-dessus est auth.login car vous l’avez ajoutée au blueprint auth.
Modèles
Vous avez écrit les vues d’authentification pour votre application, mais si vous exécutez le serveur et essayez d’aller sur l’une des URL, vous verrez une erreur TemplateNotFound. C’est parce que les vues appellent render_template(), mais vous n’avez pas encore écrit les modèles. Les fichiers de modèles seront stockés dans le répertoire templates du paquet flaskr.
Les modèles sont des fichiers qui contiennent des données statiques ainsi que des espaces réservés pour des données dynamiques. Un modèle est rendu avec des données spécifiques pour produire un document final. Flask utilise la bibliothèque de modèles Jinja pour rendre les modèles.
Dans votre application, vous utiliserez des modèles pour rendre le HTML qui s’affichera dans le navigateur de l’utilisateur. Dans Flask, Jinja est configuré pour auto-échapper toutes les données qui sont rendues dans les modèles HTML. Cela signifie que le rendu de la saisie de l’utilisateur est sûr ; tous les caractères qu’il a entrés et qui pourraient perturber le HTML, tels que < et >, seront échappés avec des valeurs sûres qui auront le même aspect dans le navigateur mais ne provoqueront pas d’effets indésirables.
Jinja se présente et se comporte essentiellement comme Python. Des délimiteurs spéciaux sont utilisés pour distinguer la syntaxe Jinja des données statiques du modèle. Tout ce qui se trouve entre {{ et }} est une expression qui sera affichée dans le document final. {% et %} dénote une instruction de flux de contrôle comme if et for. Contrairement à Python, les blocs sont désignés par des balises de début et de fin plutôt que par une indentation, car le texte statique à l’intérieur d’un bloc peut modifier l’indentation.
La disposition de la base
Chaque page de l’application aura la même mise en page de base autour d’un corps différent. Au lieu d’écrire la structure HTML complète dans chaque modèle, chaque modèle étendra un modèle de base et remplacera des sections spécifiques.
flaskr/templates/base.html :
<!doctype html>
<title>{% block title %}{% endblock %} - Flaskr</title>
<link rel="stylesheet" href="{{ url_for('static', filename='style.css') }}">
<nav>
<h1>Flaskr</h1>
<ul>
{% if g.user %}
<li><span>{{ g.user['username'] }}</span>
<li><a href="{{ url_for('auth.logout') }}">Log Out</a>
{% else %}
<li><a href="{{ url_for('auth.register') }}">Register</a>
<li><a href="{{ url_for('auth.login') }}">Log In</a>
{% endif %}
</ul>
</nav>
<section class="content">
<header>
{% block header %}{% endblock %}
</header>
{% for message in get_flashed_messages() %}
<div class="flash">{{ message }}</div>
{% endfor %}
{% block content %}{% endblock %}
</section>
g est automatiquement disponible dans les modèles. Selon que g.user est défini (à partir de load_logged_in_user), soit le nom d’utilisateur et un lien de déconnexion sont affichés, soit des liens pour s’enregistrer et se connecter sont affichés. url_for() est aussi automatiquement disponible, et est utilisé pour générer des URLs pour les vues au lieu de les écrire manuellement.
Après le titre de la page, et avant le contenu, le modèle boucle sur chaque message renvoyé par get_flashed_messages(). Vous avez utilisé flash() dans les vues pour afficher les messages d’erreur, et voici le code qui va les afficher.
Il y a trois blocs définis ici qui seront remplacés dans les autres modèles :
{% block title %}modifiera le titre affiché dans l’onglet et le titre de la fenêtre du navigateur.{% block header %}est similaire à title mais changera le titre affiché sur la page.{% block content %}est l’endroit où va le contenu de chaque page, comme le formulaire de connexion ou un article de blog.
Le modèle de base se trouve directement dans le répertoire templates. Pour garder les autres organisés, les modèles pour un blueprint seront placés dans un répertoire avec le même nom que le blueprint.
S’inscrire
flaskr/templates/auth/register.html :
{% extends 'base.html' %}
{% block header %}
<h1>{% block title %}Register{% endblock %}</h1>
{% endblock %}
{% block content %}
<form method="post">
<label for="username">Username</label>
<input name="username" id="username" required>
<label for="password">Password</label>
<input type="password" name="password" id="password" required>
<input type="submit" value="Register">
</form>
{% endblock %}
{% extends 'base.html' %} indique à Jinja que ce modèle doit remplacer les blocs du modèle de base. Tout le contenu rendu doit apparaître à l’intérieur des balises {% block %} qui remplacent les blocs du modèle de base.
Un modèle utile utilisé ici consiste à placer {% block title %} à l’intérieur de {% block header %}. Cela permettra de définir le bloc title puis d’afficher sa valeur dans le bloc header, de sorte que la fenêtre et la page partagent le même titre sans l’écrire deux fois.
Les balises input utilisent ici l’attribut required. Cela indique au navigateur de ne pas soumettre le formulaire tant que ces champs ne sont pas remplis. Si l’utilisateur utilise un ancien navigateur qui ne prend pas en charge cet attribut, ou s’il utilise autre chose qu’un navigateur pour faire des requêtes, vous devez quand même valider les données dans la vue Flask. Il est important de toujours valider complètement les données sur le serveur, même si le client effectue également une certaine validation.
Connexion
Ce modèle est identique au modèle pour s’inscrire, à l’exception du titre et du bouton d’envoi.
flaskr/templates/auth/login.html :
{% extends 'base.html' %}
{% block header %}
<h1>{% block title %}Log In{% endblock %}</h1>
{% endblock %}
{% block content %}
<form method="post">
<label for="username">Username</label>
<input name="username" id="username" required>
<label for="password">Password</label>
<input type="password" name="password" id="password" required>
<input type="submit" value="Log In">
</form>
{% endblock %}
Inscrire un utilisateur
Maintenant que les modèles d’authentification sont écrits, vous pouvez enregistrer un utilisateur. Assurez-vous que le serveur est toujours en cours d’exécution (flask run s’il ne l’est pas), puis allez à http://127.0.0.1:5000/auth/register.
Essayez de cliquer sur le bouton « Register » sans remplir le formulaire et voyez si le navigateur affiche un message d’erreur. Essayez de supprimer les attributs required du modèle register.html et cliquez à nouveau sur « Register ». Au lieu que le navigateur affiche une erreur, la page se recharge et l’erreur de flash() dans la vue s’affiche.
Remplissez un nom d’utilisateur et un mot de passe et vous serez redirigé vers la page de connexion. Essayez de saisir un nom d’utilisateur incorrect, ou un nom d’utilisateur correct et un mot de passe incorrect. Si vous vous connectez, vous obtiendrez une erreur car il n’y a pas encore de vue index vers laquelle rediriger.
Fichiers statiques
Les vues et les modèles d’authentification fonctionnent, mais ils sont très simples pour le moment. Un peu de CSS peut être ajouté pour ajouter du style à la mise en page HTML que vous avez construite. Le style ne changera pas, il s’agit donc d’un fichier statique plutôt que d’un modèle.
Flask ajoute automatiquement une vue static qui prend un chemin relatif au répertoire flaskr/static et le sert. Le modèle base.html a déjà un lien vers le fichier style.css :
{{ url_for('static', filename='style.css') }}
Outre les CSS, d’autres types de fichiers statiques peuvent être des fichiers contenant des fonctions JavaScript, ou une image de logo. Ils sont tous placés dans le répertoire flaskr/static et référencés avec url_for('static', filename='...').
Ce tutoriel n’est pas axé sur l’écriture de CSS, vous pouvez donc simplement copier ce qui suit dans le fichier flaskr/static/style.css :
flaskr/static/style.css :
html { font-family: sans-serif; background: #eee; padding: 1rem; }
body { max-width: 960px; margin: 0 auto; background: white; }
h1 { font-family: serif; color: #377ba8; margin: 1rem 0; }
a { color: #377ba8; }
hr { border: none; border-top: 1px solid lightgray; }
nav { background: lightgray; display: flex; align-items: center; padding: 0 0.5rem; }
nav h1 { flex: auto; margin: 0; }
nav h1 a { text-decoration: none; padding: 0.25rem 0.5rem; }
nav ul { display: flex; list-style: none; margin: 0; padding: 0; }
nav ul li a, nav ul li span, header .action { display: block; padding: 0.5rem; }
.content { padding: 0 1rem 1rem; }
.content > header { border-bottom: 1px solid lightgray; display: flex; align-items: flex-end; }
.content > header h1 { flex: auto; margin: 1rem 0 0.25rem 0; }
.flash { margin: 1em 0; padding: 1em; background: #cae6f6; border: 1px solid #377ba8; }
.post > header { display: flex; align-items: flex-end; font-size: 0.85em; }
.post > header > div:first-of-type { flex: auto; }
.post > header h1 { font-size: 1.5em; margin-bottom: 0; }
.post .about { color: slategray; font-style: italic; }
.post .body { white-space: pre-line; }
.content:last-child { margin-bottom: 0; }
.content form { margin: 1em 0; display: flex; flex-direction: column; }
.content label { font-weight: bold; margin-bottom: 0.5em; }
.content input, .content textarea { margin-bottom: 1em; }
.content textarea { min-height: 12em; resize: vertical; }
input.danger { color: #cc2f2e; }
input[type=submit] { align-self: start; min-width: 10em; }
Vous pouvez trouver une version moins compacte de style.css dans le code d’exemple.
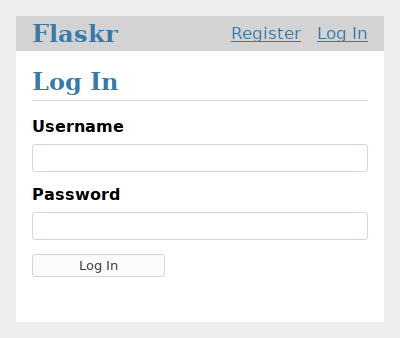
Allez sur http://127.0.0.1:5000/auth/login et la page devrait ressembler à la capture d’écran ci-dessous.
Vous pouvez en savoir plus sur les CSS en consultant Mozilla’s documentation. Si vous modifiez un fichier statique, rafraîchissez la page du navigateur. Si la modification ne s’affiche pas, essayez de vider le cache de votre navigateur.
Blueprint du blog
Vous utiliserez les mêmes techniques que celles que vous avez apprises lors de l’écriture du modèle d’authentification pour écrire le modèle du blog. Le blog doit lister tous les messages, permettre aux utilisateurs connectés de créer des messages et permettre à l’auteur d’un message de le modifier ou de le supprimer.
À mesure que vous implémentez chaque vue, laissez le serveur de développement fonctionner. Lorsque vous enregistrez vos modifications, essayez d’aller à l’URL dans votre navigateur et de les tester.
Le blueprint
Définir le blueprint et l’enregistrer dans la fabrique d’applications.
flaskr/blog.py :
from flask import (
Blueprint, flash, g, redirect, render_template, request, url_for
)
from werkzeug.exceptions import abort
from flaskr.auth import login_required
from flaskr.db import get_db
bp = Blueprint('blog', __name__)
Importez et enregistrez le blueprint depuis la fabrique en utilisant app.register_blueprint(). Placez le nouveau code à la fin de la fonction de la fabrique avant de retourner l’application.
flaskr/init.py :
def create_app():
app = ...
# existing code omitted
from . import blog
app.register_blueprint(blog.bp)
app.add_url_rule('/', endpoint='index')
return app
Contrairement au blueprint pour l’authentification, le blueprint du blog n’a pas d’url_prefix. Donc la vue index sera à /, la vue create à /create, et ainsi de suite. Le blog est la fonctionnalité principale de Flaskr, il est donc logique que l’index du blog soit l’index principal.
Cependant, le point de terminaison pour la vue index définie ci-dessous sera blog.index. Certaines vues d’authentification se référaient à un point de terminaison index simple. app.add_url_rule() associe le nom du point de terminaison ‘index’ à l’url / de sorte que url_for('index') ou url_for('blog.index') fonctionneront tous les deux, générant la même URL / dans les deux cas.
Dans une autre application, vous pourriez donner au blueprint du blog un url_prefix et définir une vue index distincte dans la fabrique d’application, similaire à la vue hello. Les URLs et les points de terminaison index et blog.index seraient alors différents.
Index
L’index montrera tous les messages, les plus récents en premier. Un JOIN est utilisé pour que les informations sur l’auteur provenant de la table user soient disponibles dans le résultat.
flaskr/blog.py :
@bp.route('/')
def index():
db = get_db()
posts = db.execute(
'SELECT p.id, title, body, created, author_id, username'
' FROM post p JOIN user u ON p.author_id = u.id'
' ORDER BY created DESC'
).fetchall()
return render_template('blog/index.html', posts=posts)
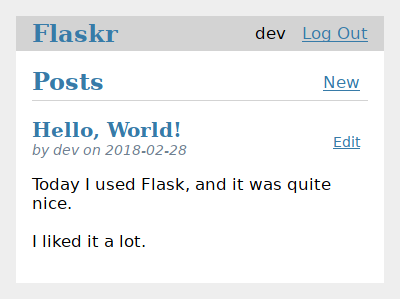
flaskr/templates/blog/index.html :
{% extends 'base.html' %}
{% block header %}
<h1>{% block title %}Posts{% endblock %}</h1>
{% if g.user %}
<a class="action" href="{{ url_for('blog.create') }}">New</a>
{% endif %}
{% endblock %}
{% block content %}
{% for post in posts %}
<article class="post">
<header>
<div>
<h1>{{ post['title'] }}</h1>
<div class="about">by {{ post['username'] }} on {{ post['created'].strftime('%Y-%m-%d') }}</div>
</div>
{% if g.user['id'] == post['author_id'] %}
<a class="action" href="{{ url_for('blog.update', id=post['id']) }}">Edit</a>
{% endif %}
</header>
<p class="body">{{ post['body'] }}</p>
</article>
{% if not loop.last %}
<hr>
{% endif %}
{% endfor %}
{% endblock %}
Lorsqu’un utilisateur est connecté, le bloc header ajoute un lien vers la vue create. Lorsque l’utilisateur est l’auteur d’un message, il verra un lien « Editer » vers la vue update de ce message. loop.last est une variable spéciale disponible dans Jinja for loops. Elle est utilisée pour afficher une ligne après chaque message, sauf le dernier, afin de les séparer visuellement.
Créer
La vue create fonctionne de la même manière que la vue register d’authentification. Soit le formulaire est affiché, soit les données postées sont validées et le message est ajouté à la base de données, soit une erreur est affichée.
Le décorateur login_required que vous avez écrit plus tôt est utilisé sur les vues du blog. Un utilisateur doit être connecté pour visiter ces vues, sinon il sera redirigé vers la page de connexion.
flaskr/blog.py :
@bp.route('/create', methods=('GET', 'POST'))
@login_required
def create():
if request.method == 'POST':
title = request.form['title']
body = request.form['body']
error = None
if not title:
error = 'Title is required.'
if error is not None:
flash(error)
else:
db = get_db()
db.execute(
'INSERT INTO post (title, body, author_id)'
' VALUES (?, ?, ?)',
(title, body, g.user['id'])
)
db.commit()
return redirect(url_for('blog.index'))
return render_template('blog/create.html')
flaskr/templates/blog/create.html :
{% extends 'base.html' %}
{% block header %}
<h1>{% block title %}New Post{% endblock %}</h1>
{% endblock %}
{% block content %}
<form method="post">
<label for="title">Title</label>
<input name="title" id="title" value="{{ request.form['title'] }}" required>
<label for="body">Body</label>
<textarea name="body" id="body">{{ request.form['body'] }}</textarea>
<input type="submit" value="Save">
</form>
{% endblock %}
Mise à jour
Les vues update et delete devront toutes deux récupérer un post par id et vérifier si l’auteur correspond à l’utilisateur connecté. Pour éviter de dupliquer le code, vous pouvez écrire une fonction pour récupérer le post et l’appeler depuis chaque vue.
flaskr/blog.py :
def get_post(id, check_author=True):
post = get_db().execute(
'SELECT p.id, title, body, created, author_id, username'
' FROM post p JOIN user u ON p.author_id = u.id'
' WHERE p.id = ?',
(id,)
).fetchone()
if post is None:
abort(404, f"Post id {id} doesn't exist.")
if check_author and post['author_id'] != g.user['id']:
abort(403)
return post
abort() lèvera une exception spéciale qui renverra un code d’état HTTP. Il prend un message optionnel à afficher avec l’erreur, sinon un message par défaut est utilisé. 404 signifie « Not Found », et 403 signifie « Forbidden ». (401 signifie « Non autorisé », mais vous redirigez vers la page de connexion au lieu de renvoyer ce statut).
L’argument check_author est défini pour que la fonction puisse être utilisée pour obtenir un post sans vérifier l’auteur. Ce serait utile si vous écriviez une vue pour montrer un article individuel sur une page, où l’utilisateur n’a pas d’importance parce qu’il ne modifie pas l’article.
flaskr/blog.py :
@bp.route('/<int:id>/update', methods=('GET', 'POST'))
@login_required
def update(id):
post = get_post(id)
if request.method == 'POST':
title = request.form['title']
body = request.form['body']
error = None
if not title:
error = 'Title is required.'
if error is not None:
flash(error)
else:
db = get_db()
db.execute(
'UPDATE post SET title = ?, body = ?'
' WHERE id = ?',
(title, body, id)
)
db.commit()
return redirect(url_for('blog.index'))
return render_template('blog/update.html', post=post)
Contrairement aux vues que vous avez écrites jusqu’à présent, la fonction update prend un argument, id. Cela correspond au <int:id> dans l’URL. Une vraie URL ressemblera à /1/update. Flask va capturer le 1, s’assurer que c’est un int, et le passer comme argument id. Si vous ne spécifiez pas int: et faites plutôt
Les vues create et update sont très similaires. La principale différence est que la vue update utilise un objet post et une requête UPDATE au lieu d’une INSERT. Avec une refactorisation intelligente, vous pourriez utiliser une vue et un modèle pour les deux actions, mais pour le tutoriel, il est plus clair de les garder séparés.
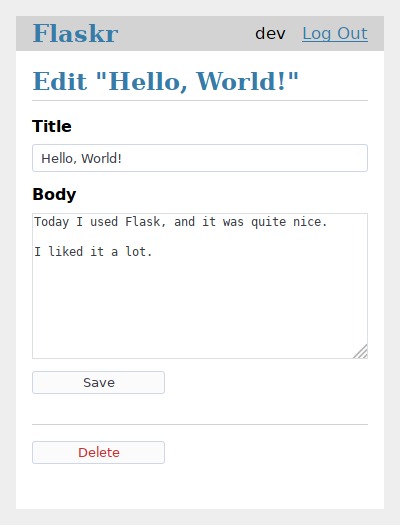
flaskr/templates/blog/update.html :
{% extends 'base.html' %}
{% block header %}
<h1>{% block title %}Edit "{{ post['title'] }}"{% endblock %}</h1>
{% endblock %}
{% block content %}
<form method="post">
<label for="title">Title</label>
<input name="title" id="title"
value="{{ request.form['title'] or post['title'] }}" required>
<label for="body">Body</label>
<textarea name="body" id="body">{{ request.form['body'] or post['body'] }}</textarea>
<input type="submit" value="Save">
</form>
<hr>
<form action="{{ url_for('blog.delete', id=post['id']) }}" method="post">
<input class="danger" type="submit" value="Delete" onclick="return confirm('Are you sure?');">
</form>
{% endblock %}
Ce modèle a deux formes. Le premier affiche les données modifiées sur la page actuelle (/<id>/update). L’autre formulaire ne contient qu’un bouton et spécifie un attribut action qui affiche la vue de suppression à la place. Le bouton utilise du JavaScript pour afficher une boîte de dialogue de confirmation avant l’envoi.
Le motif {{ request.form['title'] or post['title'] }} est utilisé pour choisir les données qui apparaissent dans le formulaire. Lorsque le formulaire n’a pas été soumis, les données originales post apparaissent, mais si des données de formulaire invalides ont été postées, vous voulez les afficher pour que l’utilisateur puisse corriger l’erreur, donc request.form est utilisé à la place. request est une autre variable qui est automatiquement disponible dans les modèles.
##### Supprimer
La vue de suppression n’a pas son propre modèle, le bouton de suppression fait partie de update.html et renvoie à l’URL /<id>/delete. Puisqu’il n’y a pas de modèle, il ne traitera que la méthode POST et redirigera ensuite vers la vue index.
flaskr/blog.py :
@bp.route('/<int:id>/delete', methods=('POST',))
@login_required
def delete(id):
get_post(id)
db = get_db()
db.execute('DELETE FROM post WHERE id = ?', (id,))
db.commit()
return redirect(url_for('blog.index'))
Félicitations, vous avez maintenant fini d’écrire votre application ! Prenez le temps de tout essayer dans le navigateur. Cependant, il reste encore beaucoup à faire avant que le projet ne soit complet.
Rendre le projet installable
Rendre votre projet installable signifie que vous pouvez créer un fichier de distribution et l’installer dans un autre environnement, tout comme vous avez installé Flask dans l’environnement de votre projet. Cela rend le déploiement de votre projet identique à l’installation de n’importe quelle autre bibliothèque, de sorte que vous utilisez tous les outils Python standard pour tout gérer.
L’installation s’accompagne également d’autres avantages qui ne sont peut-être pas évidents à la lecture du tutoriel ou en tant que nouvel utilisateur de Python, notamment :
- Actuellement, Python et Flask comprennent comment utiliser le paquet `flaskr` uniquement parce que vous vous exécutez depuis le répertoire de votre projet. L’installation signifie que vous pouvez l’importer quel que soit l’endroit d’où vous vous exécutez.
- Vous pouvez gérer les dépendances de votre projet comme les autres paquets, pour que `pip install yourproject.whl` les installe.
- Les outils de test peuvent isoler votre environnement de test de votre environnement de développement.
📝 Cette fonction est introduite tardivement dans le tutoriel, mais dans vos futurs projets, vous devriez toujours commencer par cette fonction.
Décrire le projet
Le fichier setup.py décrit votre projet et les fichiers qui lui appartiennent.
setup.py :
from setuptools import find_packages, setup
setup(
name='flaskr',
version='1.0.0',
packages=find_packages(),
include_package_data=True,
zip_safe=False,
install_requires=[
'flask',
],
)
packages indique à Python les répertoires de paquets (et les fichiers Python qu’ils contiennent) à inclure. find_packages() trouve ces répertoires automatiquement pour que vous n’ayez pas à les taper. Pour inclure d’autres fichiers, comme les répertoires static et templates, il faut définir include_package_data. Python a besoin d’un autre fichier nommé MANIFEST.in pour indiquer ce que sont ces autres données.
MANIFEST.in :
include flaskr/schema.sql
graft flaskr/static
graft flaskr/templates
global-exclude *.pyc
Ceci indique à Python de copier tout ce qui se trouve dans les répertoires static et templates, et le fichier schema.sql, mais d’exclure tous les fichiers de bytecode.
Voir le guide officiel de packaging pour une autre explication des fichiers et options utilisés.
Installer le projet
Utilisez pip pour installer votre projet dans l’environnement virtuel.
$ pip install -e .
Ceci indique à pip de trouver setup.py dans le répertoire courant et de l’installer en mode éditable ou développement. Le mode éditable signifie que lorsque vous apportez des modifications à votre code local, vous n’aurez à réinstaller que si vous changez les métadonnées du projet, comme ses dépendances.
Vous pouvez observer que le projet est maintenant installé avec pip list.
$ pip list
Package Version Location
-------------- --------- ----------------------------------
click 6.7
Flask 1.0
flaskr 1.0.0 /home/user/Projects/flask-tutorial
itsdangerous 0.24
Jinja2 2.10
MarkupSafe 1.0
pip 9.0.3
setuptools 39.0.1
Werkzeug 0.14.1
wheel 0.30.0
Rien ne change par rapport à la façon dont vous avez exécuté votre projet jusqu’à présent. FLASK_APP est toujours défini à flaskr et flask run exécute toujours l’application, mais vous pouvez l’appeler de n’importe où, pas seulement du répertoire flask-tutorial.
Couverture des tests
L’écriture de tests unitaires pour votre application vous permet de vérifier que le code que vous avez écrit fonctionne comme vous l’attendez. Flask fournit un client de test qui simule les requêtes adressées à l’application et renvoie les données de réponse.
Vous devez tester votre code autant que possible. Le code des fonctions ne s’exécute que lorsque la fonction est appelée, et le code des embranchements, comme les blocs if, ne s’exécute que lorsque la condition est remplie. Vous devez vous assurer que chaque fonction est testée avec des données qui couvrent chaque branche.
Plus vous vous rapprochez d’une couverture de 100 %, plus vous pouvez être sûr qu’un changement ne modifiera pas de manière inattendue d’autres comportements. Cependant, une couverture à 100 % ne garantit pas que votre application ne comporte pas de bogues. En particulier, elle ne permet pas de tester la manière dont l’utilisateur interagit avec l’application dans le navigateur. Malgré cela, la couverture des tests est un outil important à utiliser pendant le développement.
📝 Ce point est introduit tardivement dans le tutoriel, mais dans vos futurs projets, vous devriez tester au fur et à mesure que vous développez.
Vous utiliserez pytest et coverage pour tester et mesurer votre code. Installez-les tous les deux :
$ pip install pytest coverage
Installation et fixtures
Le code de test est situé dans le répertoire tests. Ce répertoire se trouve à côté du paquet flaskr, pas à l’intérieur. Le fichier tests/conftest.py contient des fonctions de configuration appelées fixtures que chaque test utilisera. Les tests sont dans des modules Python qui commencent par test_, et chaque fonction de test dans ces modules commence aussi par test_.
Chaque test créera un nouveau fichier de base de données temporaire et alimentera certaines données qui seront utilisées dans les tests. Écrivez un fichier SQL pour insérer ces données.
tests/data.sql :
INSERT INTO user (username, password)
VALUES
('test', 'pbkdf2:sha256:50000$TCI4GzcX$0de171a4f4dac32e3364c7ddc7c14f3e2fa61f2d17574483f7ffbb431b4acb2f'),
('other', 'pbkdf2:sha256:50000$kJPKsz6N$d2d4784f1b030a9761f5ccaeeaca413f27f2ecb76d6168407af962ddce849f79');
INSERT INTO post (title, body, author_id, created)
VALUES
('test title', 'test' || x'0a' || 'body', 1, '2018-01-01 00:00:00');
La fixture app appelle la fabrique et passe test_config pour configurer l’application et la base de données pour les tests au lieu d’utiliser votre configuration de développement locale.
tests/conftest.py :
import os
import tempfile
import pytest
from flaskr import create_app
from flaskr.db import get_db, init_db
with open(os.path.join(os.path.dirname(__file__), 'data.sql'), 'rb') as f:
_data_sql = f.read().decode('utf8')
@pytest.fixture
def app():
db_fd, db_path = tempfile.mkstemp()
app = create_app({
'TESTING': True,
'DATABASE': db_path,
})
with app.app_context():
init_db()
get_db().executescript(_data_sql)
yield app
os.close(db_fd)
os.unlink(db_path)
@pytest.fixture
def client(app):
return app.test_client()
@pytest.fixture
def runner(app):
return app.test_cli_runner()
tempfile.mkstemp() crée et ouvre un fichier temporaire, renvoyant le descripteur de fichier et le chemin d’accès à celui-ci. Le chemin d’accès à la DATABASE est remplacé par le chemin d’accès temporaire au lieu du dossier de l’instance. Après avoir défini le chemin, les tables de la base de données sont créées et les données du test sont insérées. Une fois le test terminé, le fichier temporaire est fermé et supprimé.
TESTING indique à Flask que l’application est en mode test. Flask modifie certains comportements internes pour faciliter les tests, et d’autres extensions peuvent également utiliser ce flag pour faciliter leurs tests.
La fixture client appelle app.test_client() avec l’objet application créé par la fixture app. Les tests utiliseront le client pour faire des requêtes à l’application sans démarrer le serveur.
La fixture runner est similaire à client. app.test_cli_runner() crée un runner qui peut appeler les commandes Click enregistrées avec l’application.
Pytest utilise les fixtures en faisant correspondre leurs noms de fonctions avec les noms des arguments dans les fonctions de test. Par exemple, la fonction test_hello que vous allez écrire ensuite prend un argument client. Pytest fait correspondre cet argument avec la fonction fixture client, l’appelle et passe la valeur retournée à la fonction de test.
Fabrique
Il n’y a pas grand chose à tester sur l’usine elle-même. La plupart du code sera déjà exécuté pour chaque test, donc si quelque chose échoue, les autres tests le remarqueront.
Le seul comportement qui peut changer est le passage du test config. Si la configuration n’est pas passée, il doit y avoir une configuration par défaut, sinon la configuration doit être remplacée.
tests/test_factory.py :
from flaskr import create_app
def test_config():
assert not create_app().testing
assert create_app({'TESTING': True}).testing
def test_hello(client):
response = client.get('/hello')
assert response.data == b'Hello, World!'
Vous avez ajouté la route hello comme exemple lors de l’écriture de la fabrique au début du tutoriel. Il retourne « Hello, World ! », donc le test vérifie que les données de la réponse correspondent.
Base de données
Dans un contexte d’application, get_db doit retourner la même connexion à chaque fois qu’il est appelé. Après le contexte, la connexion doit être fermée.
tests/test_db.py ;
import sqlite3
import pytest
from flaskr.db import get_db
def test_get_close_db(app):
with app.app_context():
db = get_db()
assert db is get_db()
with pytest.raises(sqlite3.ProgrammingError) as e:
db.execute('SELECT 1')
assert 'closed' in str(e.value)
La commande init-db devrait appeler la fonction init_db et produire un message.
tests/test_db.py :
def test_init_db_command(runner, monkeypatch):
class Recorder(object):
called = False
def fake_init_db():
Recorder.called = True
monkeypatch.setattr('flaskr.db.init_db', fake_init_db)
result = runner.invoke(args=['init-db'])
assert 'Initialized' in result.output
assert Recorder.called
Ce test utilise la fixture monkeypatch de Pytest pour remplacer la fonction init_db par une fonction qui enregistre qu’elle a été appelée. La fixture runner que vous avez écrite ci-dessus est utilisée pour appeler la commande init-db par son nom.
Authentification
Pour la plupart des vues, un utilisateur doit être connecté. La façon la plus simple de faire cela dans les tests est de faire une requête POST vers la vue login avec le client. Plutôt que d’écrire cela à chaque fois, vous pouvez écrire une classe avec des méthodes pour le faire, et utiliser une fixture pour lui passer le client pour chaque test.
tests/conftest.py :
class AuthActions(object):
def __init__(self, client):
self._client = client
def login(self, username='test', password='test'):
return self._client.post(
'/auth/login',
data={'username': username, 'password': password}
)
def logout(self):
return self._client.get('/auth/logout')
@pytest.fixture
def auth(client):
return AuthActions(client)
Avec la fixture auth, vous pouvez appeler auth.login() dans un test pour vous connecter en tant qu’utilisateur test, qui a été inséré comme partie des données de test dans l’interface app.
La vue register doit être rendue avec succès sur GET. Sur POST avec des données de formulaire valides, elle devrait rediriger vers l’URL de connexion et les données de l’utilisateur devraient être dans la base de données. Les données non valides doivent afficher des messages d’erreur.
tests/test_auth.py :
import pytest
from flask import g, session
from flaskr.db import get_db
def test_register(client, app):
assert client.get('/auth/register').status_code == 200
response = client.post(
'/auth/register', data={'username': 'a', 'password': 'a'}
)
assert 'http://localhost/auth/login' == response.headers['Location']
with app.app_context():
assert get_db().execute(
"select * from user where username = 'a'",
).fetchone() is not None
@pytest.mark.parametrize(('username', 'password', 'message'), (
('', '', b'Username is required.'),
('a', '', b'Password is required.'),
('test', 'test', b'already registered'),
))
def test_register_validate_input(client, username, password, message):
response = client.post(
'/auth/register',
data={'username': username, 'password': password}
)
assert message in response.data
client.get() fait une requête GET et renvoie l’objet Response retourné par Flask. De même, client.post() fait une requête POST, convertissant le dictionnaire data en données de formulaire.
Pour tester que la page s’affiche correctement, une simple requête est effectuée et on vérifie si elle renvoie un code 200 OK status_code Si le rendu échoue, Flask renvoie un code 500 Internal Server Error.
headers aura un en-tête Location avec l’URL de connexion lorsque la vue d’enregistrement redirige vers la vue de connexion.
data contient le corps de la réponse sous forme d’octets. Si vous vous attendez à ce qu’une certaine valeur soit rendue sur la page, vérifiez qu’elle se trouve dans data. Les octets doivent être comparés à des octets. Si vous voulez comparer du texte, utilisez get_data(as_text=True) à la place.
pytest.mark.parametrize indique à Pytest d’exécuter la même fonction de test avec différents arguments. Vous l’utilisez ici pour tester différentes entrées invalides et différents messages d’erreur sans écrire le même code trois fois.
Les tests pour la vue login sont très similaires à ceux de register. Plutôt que de tester les données dans la base de données, session devrait avoir user_id défini après la connexion.
tests/test_auth.py :
def test_login(client, auth):
assert client.get('/auth/login').status_code == 200
response = auth.login()
assert response.headers['Location'] == 'http://localhost/'
with client:
client.get('/')
assert session['user_id'] == 1
assert g.user['username'] == 'test'
@pytest.mark.parametrize(('username', 'password', 'message'), (
('a', 'test', b'Incorrect username.'),
('test', 'a', b'Incorrect password.'),
))
def test_login_validate_input(auth, username, password, message):
response = auth.login(username, password)
assert message in response.data
L’utilisation de client dans un bloc with permet d’accéder à des variables contextuelles telles que session après le retour de la réponse. Normalement, l’accès à session en dehors d’une requête soulève une erreur.
Le test logout est le contraire de login. session ne doit pas contenir user_id après la déconnexion.
tests/test_auth.py :
def test_logout(client, auth):
auth.login()
with client:
auth.logout()
assert 'user_id' not in session
Blog
Toutes les vues du blog utilisent la fixture auth que vous avez écrit plus tôt. Appelez auth.login() et les requêtes suivantes du client seront connectées en tant qu’utilisateur test.
La vue index doit afficher des informations sur le message qui a été ajouté avec les données de test. Lorsque l’on est connecté en tant qu’auteur, il doit y avoir un lien pour modifier le message.
Vous pouvez également tester d’autres comportements d’authentification en testant la vue index. Lorsque vous n’êtes pas connecté, chaque page affiche des liens pour se connecter ou s’enregistrer. Lorsqu’on est connecté, il y a un lien pour se déconnecter.
tests/test_blog.py :
import pytest
from flaskr.db import get_db
def test_index(client, auth):
response = client.get('/')
assert b"Log In" in response.data
assert b"Register" in response.data
auth.login()
response = client.get('/')
assert b'Log Out' in response.data
assert b'test title' in response.data
assert b'by test on 2018-01-01' in response.data
assert b'test\nbody' in response.data
assert b'href="/1/update"' in response.data
Un utilisateur doit être connecté pour accéder aux vues create, update et delete. L’utilisateur connecté doit être l’auteur du message pour accéder à update et delete, sinon un état 403 Forbidden est renvoyé. Si un message avec l’id donné n’existe pas, update et delete doivent retourner 404 Not Found.
tests/test_blog.py :
@pytest.mark.parametrize('path', (
'/create',
'/1/update',
'/1/delete',
))
def test_login_required(client, path):
response = client.post(path)
assert response.headers['Location'] == 'http://localhost/auth/login'
def test_author_required(app, client, auth):
# change the post author to another user
with app.app_context():
db = get_db()
db.execute('UPDATE post SET author_id = 2 WHERE id = 1')
db.commit()
auth.login()
# current user can't modify other user's post
assert client.post('/1/update').status_code == 403
assert client.post('/1/delete').status_code == 403
# current user doesn't see edit link
assert b'href="/1/update"' not in client.get('/').data
@pytest.mark.parametrize('path', (
'/2/update',
'/2/delete',
))
def test_exists_required(client, auth, path):
auth.login()
assert client.post(path).status_code == 404
Les vues create et update doivent afficher et renvoyer un état 200 OK pour une requête GET. Lorsque des données valides sont envoyées dans une requête POST, la vue create doit insérer les nouvelles données du message dans la base de données et la vue update doit modifier les données existantes. Les deux pages doivent afficher un message d’erreur en cas de données invalides.
tests/test_blog.py :
def test_create(client, auth, app):
auth.login()
assert client.get('/create').status_code == 200
client.post('/create', data={'title': 'created', 'body': ''})
with app.app_context():
db = get_db()
count = db.execute('SELECT COUNT(id) FROM post').fetchone()[0]
assert count == 2
def test_update(client, auth, app):
auth.login()
assert client.get('/1/update').status_code == 200
client.post('/1/update', data={'title': 'updated', 'body': ''})
with app.app_context():
db = get_db()
post = db.execute('SELECT * FROM post WHERE id = 1').fetchone()
assert post['title'] == 'updated'
@pytest.mark.parametrize('path', (
'/create',
'/1/update',
))
def test_create_update_validate(client, auth, path):
auth.login()
response = client.post(path, data={'title': '', 'body': ''})
assert b'Title is required.' in response.data
La vue delete doit rediriger vers l’URL de l’index et le message ne doit plus exister dans la base de données.
tests/test_blog.py :
def test_delete(client, auth, app):
auth.login()
response = client.post('/1/delete')
assert response.headers['Location'] == 'http://localhost/'
with app.app_context():
db = get_db()
post = db.execute('SELECT * FROM post WHERE id = 1').fetchone()
assert post is None
Exécution des tests
Une configuration supplémentaire, qui n’est pas nécessaire mais qui rend l’exécution des tests de couverture moins verbeuse, peut être ajoutée au fichier setup.cfg du projet.
setup.cfg :
[tool:pytest]
testpaths = tests
[coverage:run]
branch = True
source =
flaskr
Pour exécuter les tests, utilisez la commande pytest. Elle trouvera et exécutera toutes les fonctions de test que vous avez écrites.
$ pytest
========================= test session starts ==========================
platform linux -- Python 3.6.4, pytest-3.5.0, py-1.5.3, pluggy-0.6.0
rootdir: /home/user/Projects/flask-tutorial, inifile: setup.cfg
collected 23 items
tests/test_auth.py ........ [ 34%]
tests/test_blog.py ............ [ 86%]
tests/test_db.py .. [ 95%]
tests/test_factory.py .. [100%]
====================== 24 passed in 0.64 seconds =======================
Si un test échoue, pytest affichera l’erreur qui a été levée. Vous pouvez lancer pytest -v pour obtenir une liste de chaque fonction de test plutôt que des points.
Pour mesurer la couverture de code de vos tests, utilisez la commande coverage pour lancer pytest au lieu de le lancer directement.
$ coverage run -m pytest
Vous pouvez soit afficher un simple rapport de couverture dans le terminal :
$ coverage report
Name Stmts Miss Branch BrPart Cover
------------------------------------------------------
flaskr/__init__.py 21 0 2 0 100%
flaskr/auth.py 54 0 22 0 100%
flaskr/blog.py 54 0 16 0 100%
flaskr/db.py 24 0 4 0 100%
------------------------------------------------------
TOTAL 153 0 44 0 100%
Un rapport HTML vous permet de voir quelles lignes ont été couvertes dans chaque fichier :
$ coverage html
Cela génère des fichiers dans le répertoire htmlcov. Ouvrez htmlcov/index.html dans votre navigateur pour voir le rapport.
Déployer en production
Cette partie du tutoriel suppose que vous disposez d’un serveur sur lequel vous souhaitez déployer votre application. Elle donne un aperçu de la manière de créer le fichier de distribution et de l’installer, mais n’entre pas dans les détails concernant le serveur ou le logiciel à utiliser. Vous pouvez configurer un nouvel environnement sur votre ordinateur de développement pour essayer les instructions ci-dessous, mais vous ne devriez probablement pas l’utiliser pour héberger une véritable application publique. Voir Deployment Options pour une liste des différentes manières d’héberger votre application.
Construction et installation
Lorsque vous voulez déployer votre application ailleurs, vous construisez un fichier de distribution. Le standard actuel pour la distribution Python est le format wheel, avec l’extension .whl. Assurez-vous que la bibliothèque wheel est installée en premier :
$ pip install wheel
L’exécution de setup.py avec Python vous donne un outil de ligne de commande pour lancer des commandes liées à la construction. La commande bdist_wheel va construire un fichier de distribution wheel.
$ python setup.py bdist_wheel
Vous pouvez trouver le fichier dans dist/flaskr-1.0.0-py3-none-any.whl. Le nom du fichier est au format {nom du projet}-{version}-{balises python} -{balise abi}-{balise plateforme}.
Copiez ce fichier sur une autre machine, mettez en place un nouveau virtualenv, puis installez le fichier avec pip.
$ pip install flaskr-1.0.0-py3-none-any.whl
Pip installera votre projet ainsi que ses dépendances.
Comme il s’agit d’une machine différente, vous devez relancer init-db pour créer la base de données dans le dossier de l’instance.
$ export FLASK_APP=flaskr
$ flask init-db
Lorsque Flask détecte qu’il est installé (pas en mode modifiable), il utilise un répertoire différent pour le dossier de l’instance. Vous pouvez le trouver dans venv/var/flaskr-instance à la place.
Configurer la clé secrète
Au début du tutoriel, vous avez donné une valeur par défaut pour SECRET_KEY. Cette valeur doit être remplacée par des octets aléatoires en production. Sinon, les attaquants pourraient utiliser la clé publique ‘dev’ pour modifier le cookie de session, ou tout autre élément qui utilise la clé secrète.
Vous pouvez utiliser la commande suivante pour générer une clé secrète aléatoire :
$ python -c 'import os; print(os.urandom(16))'
b'_5#y2L"F4Q8z\n\xec]/'
Créez le fichier config.py dans le dossier de l’instance, que la fabrique lira s’il existe. Copiez la valeur générée dans ce fichier.
venv/var/flaskr-instance/config.py :
SECRET_KEY = b'_5#y2L"F4Q8z\n\xec]/'
Vous pouvez également définir toute autre configuration nécessaire ici, bien que SECRET_KEY soit la seule nécessaire pour Flaskr.
Exécution avec un serveur de production
Lorsque vous exécutez publiquement plutôt qu’en développement, vous ne devriez pas utiliser le serveur de développement intégré (flask run). Le serveur de développement est fourni par Werkzeug pour des raisons pratiques, mais il n’est pas conçu pour être particulièrement efficace, stable ou sécurisé.
A la place, utilisez un serveur WSGI de production. Par exemple, pour utiliser Waitress, installez-le d’abord dans l’environnement virtuel :
$ pip install waitress
Vous devez informer Waitress de votre application, mais il n’utilise pas FLASK_APP comme le fait flask run. Vous devez lui dire d’importer et d’appeler la fabrique d’applications pour obtenir un objet d’application.
$ waitress-serve --call 'flaskr:create_app'
Serving on http://0.0.0.0:8080
Voir Deployment Options pour une liste des différentes manières d’héberger votre application. Waitress est juste un exemple, choisi pour le tutoriel parce qu’il supporte à la fois Windows et Linux. Il existe de nombreux autres serveurs WSGI et options de déploiement que vous pouvez choisir pour votre projet.
Continuez à vous développer !
Vous avez appris un certain nombre de concepts de Flask et de Python tout au long du tutoriel. Revenez en arrière, relisez le tutoriel et comparez votre code avec les étapes que vous avez suivies pour y arriver. Comparez votre projet au projet exemple, qui pourrait avoir un aspect un peu différent en raison de la nature pas à pas du tutoriel.
Flask est bien plus que ce que vous avez vu jusqu’à présent. Néanmoins, vous êtes maintenant équipé pour commencer à développer vos propres applications web. Consultez Bien débuter pour avoir un aperçu de ce que Flask peut faire, puis plongez dans la documentation pour continuer à apprendre. Flask utilise Jinja, Click, Werkzeug, et ItsDangerous dans les coulisses, et ils ont tous leur propre documentation aussi. Vous serez également intéressé par les Extensions qui rendent des tâches comme le travail avec la base de données ou la validation des données de formulaire plus faciles et plus puissantes.
Si vous souhaitez continuer à développer votre projet Flaskr, voici quelques idées sur ce que vous pouvez essayer ensuite :
- Une vue détaillée pour afficher un seul message. Cliquez sur le titre d’un message pour accéder à sa page.
- Haut-vote / bas-vote un message.
- Commentaires.
- Tags. Si vous cliquez sur un tag, vous verrez tous les messages correspondant à ce tag.
- Une barre de recherche qui filtre la page d’index par nom.
- Affichage par page. N’affichez que 5 messages par page.
- Téléchargez une image pour accompagner un article.
- Formatez vos articles en utilisant le format Markdown.
- Un flux RSS des nouveaux messages.
Amusez-vous et faites des applications géniales !